Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Udemy Course
In this blog, I am going to explain how to write our first accelerator using the Xilinx Vitis unified platform. The algorithm is a simple version of the famous sgemv function from BLAS specification. You can extend that later to cover all the cases for this function.
The sgemv function implements the matrix-vector multiplication operator. The following equation describes this function that we are going to implement in hardware.

![y[i] = \alpha \sum_{j=0}^{m-1}{A[i][j]*x[j]}+\beta y[i]](https://s0.wp.com/latex.php?latex=y%5Bi%5D+%3D+%5Calpha+%5Csum_%7Bj%3D0%7D%5E%7Bm-1%7D%7BA%5Bi%5D%5Bj%5D%2Ax%5Bj%5D%7D%2B%5Cbeta+y%5Bi%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
where 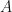



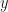


I assume that the A matrix is in memory in row-major order as shown in the following figure.

The following code shows a simple example of this function in C:
void sgemv(float *A, float *x, float *y, float a, float b) {
for (int i = 0; i < n; i++) {
float s = 0;
for (int j = 0; j < m; j++) {
s += A[i*m+j]*x[j];
}
y[i] = a*s+b*y[i];
}
}Before implementing this algorithm on hardware, it is a good idea to have a big picture of the whole system in our minds. The following picture shows the three main parts of an embedded system and how they communicate together. Both CPU (or PS) and FPGA (or PL) can communicate with the main memory through high-performance busses. They can use the burst data transfer protocol for providing high bandwidth utilization. The FPGA uses these busses to read/write an array of data from/to the main memory. Note that, the datapath implementation of these buses depends on the target hardware platform. The CPU and FPGA communicate PS-PL buses. The main goal of this communication is passing scalar arguments and hardware configuration from CPU to FPGA.

Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Udemy Course
The top function arguments in a hardware accelerator should be connected to either PL-MEMor PS-PL buses. This connection is performed through ports. So, assigned to each function argument there is a port in the final hardware design. A port can be unidirectional (only for reading or writing data) or it can be bidirectional for both reading and writing data. Note that, technically, at the HDL level, each bidirectional port is implemented by two unidirectional ports. I will explain this in the next blog. Each port consists of different numbers of signals based on the data type and interface of the associated function argument.
The following code shows the naïve hardware C-code for the sgemv function. The only difference with the software version is defining the communication ports and their associated interfaces. Lines 10 to 22 represent these definitions using a set of compiler directives.
Arrays A, x, and y are saved in the memory. Therefore, FPGA should utilize high-performance (HP) ports (connected to the PL-MEM buses) to access their data. Lines 10-12 determine using HP ports through master AXI interfaces. In addition, associated with each array, there should be a low-performance port (LP) (connected to a PS-PL bus) through which the CPU configures the corresponding interface hardware. These LP ports are defined in Lines 14-16 using AXILite interfaces.
The CPU also requires LP ports for scalar variables a, b, n, and m, which are defined in Lines 18-21. Also, there should be an LP port for the function through which CPU controls the function execution. This port is defined at Line 22 using an AXILite interface.
01 void sgemv_naive(
02 DATA_TYPE *A,
03 DATA_TYPE *x,
04 DATA_TYPE *y,
05 DATA_TYPE a,
06 DATA_TYPE b,
07 u32 n,
08 u32 m) {
09
10 #pragma HLS INTERFACE m_axi port=A offset=slave bundle=gmem0
11 #pragma HLS INTERFACE m_axi port=x offset=slave bundle=gmem1
12 #pragma HLS INTERFACE m_axi port=y offset=slave bundle=gmem2
13
14 #pragma HLS INTERFACE s_axilite port=A bundle=control
15 #pragma HLS INTERFACE s_axilite port=x bundle=control
16 #pragma HLS INTERFACE s_axilite port=y bundle=control
17
18 #pragma HLS INTERFACE s_axilite port=n bundle=control
19 #pragma HLS INTERFACE s_axilite port=m bundle=control
20 #pragma HLS INTERFACE s_axilite port=a bundle=control
21 #pragma HLS INTERFACE s_axilite port=b bundle=control
22 #pragma HLS INTERFACE s_axilite port=return bundle=control
23
24 for (int i = 0; i < n; i++) {
25 DATA_TYPE s = 0;
26 for (int j = 0; j < n; j++) {
27 s += A[i*m+j]*x[j];
28 }
29 y[i] = a*s+b*y[i];
30 }
31 }Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Udemy Course
The Xilinx Vitis synthesizes this code with Vivado-HLS to generate the corresponding HDL code and Vivado toolset synthesis that to the final bitstream. The following figure shows the block diagram of sgemv generated by Vivado-HLS.

It contains three different ports:
- The first group includes the HP ports that are named by m_axi_gmem_0, m_axi_gmem_1, m_axi_gmem_2 that are corresponding to A, x, and y, respectively.
- The second group consists of one port called s_axi_control that bundles all AxiLight interfaces on variables A, x, y, a, b, n, and m.
- The third group, aka block-level ports, consists of three ports ap_rst_n, ap_clk, and interrupt. These ports are implementing the block level interfaces defined at Line 22.
In the next blog, I will explain more about these ports.
If n=m=1024, then the execution time will be 59 msec on the Ultra96v2 board.
The source code of this function tested in Vitis-2019.2 can be found here.
Featured image source: artist: Eugenio Zampighi, Wikimedia
{kind=link}
Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Udemy Course