Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Spars matrices in which most of the elements are zeros arise in many computational applications including simulations, machine learning and so on. The equation of Equ. (1) can be considered as a sparse matrix in whcih only 8 elments out of 32 are nonzero.
 | (1) |
A collection of sparse matrices can be found at here.
Fig. 1 highlights the nonzero elements of a sparse matrix with the size of 223×472 and 


Sparse Matrix Vector Multiplication (SpMV)
The SpMV is one of the basic operators in manipulating sparse matrices in real applications. SpMV operator is the performance bottleneck in many large scale iterative algorithms such as conjugate gradient (CG) solving linear systems, eigenvalue solvers and so on. Equs. (2) and (3) represent an SpMV in which A is an sparse matrix of size 

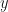
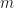

 | (2) |
 | (3) |
In a naïve scheme,
In a sparse matrix, most of these additions and multiplications are zeros and should be removed from the computation to improve performance. However, removing these zeros is not an easy task and requires a proper sparse matrix representation and computation. In general case, irregularity in non-zero elements distribution in a sparse matrix makes the computation problematic.
Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Sparse Matrix Representation
Different approaches have been proposed by researchers for representing a sparse matrix. Associated to each representation there is a computational structure to increase the performance.
Coordinate format
One of the simple representation is the coordinate (COO) format in which each nonzero element of the sparse matrix along with its indices are stored in the memory. Therefore, in an implementation, three arrays called 


 |
(4) |
 |
(5) |
 |
(6) |
Compressed sparse row format
The compressed sparse row (CSR), as the most popular representation, is similar to the COO but with less storage. In this format, 




 |
(7) |
| |
(8) |
| |
(9) |
In this case, ![ptrs[i+1]-ptrs[i]](https://s0.wp.com/latex.php?latex=ptrs%5Bi%2B1%5D-ptrs%5Bi%5D&bg=%23ffffff&fg=%23111111&s=0&c=20201002)
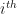
Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
Modified compressed sparse row format
To implement the CSR in FPGA, we slightly modify the CSR format (called MCSR) and replace the 


 |
(10) |
| |
(11) |
| |
(12) |
Implementation
The following code can implement the SpMV on the Xilinx Zynq SoC using SDSoC
[code language="C"]
void spmv_accel(
REAL_DATA_TYPE values[MODIFIED_DATA_LENGTH],
INT_DATA_TYPE cols[COLS],
INT_DATA_TYPE rows[ROWS],
REAL_DATA_TYPE x[COLS],
REAL_DATA_TYPE y[ROWS],
u32 max_n,
u32 row_size,
u32 col_size,
u32 data_size
) {
REAL_DATA_TYPE x_local[MAX_COL_SIZE];
u32 col_left=0;
REAL_DATA_TYPE um;
REAL_DATA_TYPE value;
u32 col;
int row_index = 0;
for(u32 i = 0; i < col_size; i++) {
#pragma HLS PIPELINE
x_local[i] = x[i];
}
for(u32 r = 0; r < data_size; r++) {
#pragma HLS PIPELINE
if (col_left == 0) {
col_left = rows[row_index];
sum = 0;
}
value = values[r];
col = cols[r];
sum += value * x_local[col];
col_left--;
if(col_left == 0) {
y[row_index++] = sum;
}
}
}
[/code]
The competer code can be found at here.
Digital System Design with High-Level Synthesis for FPGA: Combinational Circuits
